核心模型算法详解
星途数据洞察平台的核心能力建立在三大经典多变量统计模型之上:PCA(主成分分析)、**PLS(偏最小二乘回归)**和 PLS-DA(偏最小二乘判别分析)。
本章将深入剖析这三种算法的原理、适用场景、数学本质,以及在平台中的具体应用。理解这些模型,将帮助你更好地解读分析结果,做 出更精准的数据决策。
📊 模型家族概览
在深入细节之前,让我们先用一张图看清三者的关系:
┌─────────────────────────────────────────────────────────────┐
│ 多变量数据分析模型家族 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ 无监督 │ │ 有监督 │ │
│ │ Unsupervised│ │ Supervised │ │
│ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ PCA │ │ PLS │ │
│ │ 探索结构 │ │ 回归预测 │ │
│ │ 发现模式 │ │ X → Y 关系 │ │
│ └──────────────┘ └──────┬───────┘ │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ PLS-DA │ │
│ │ 分类判别 │ │
│ │ Y是类别标签 │ │
│ └──────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘一句话总结:
- PCA:"数据长什么样?" → 探索内在结构
- PLS:"X 如何影响 Y?" → 建立预测关系
- PLS-DA:"属于哪一类?" → 进行分类判别
🔬 PCA(主成分分析)
什么是 PCA?
PCA(Principal Component Analysis,主成分分析) 是一种无监督的降维技术。它的核心思想是:用更少的新变量(主成分), 尽可能保留原始数据的大部分信息。
想象你有一组三维数据点,PCA 就是找到一个最佳的二维平面,让这些点投影到平面上后,"散开程度"最大——这样信息损失最小。
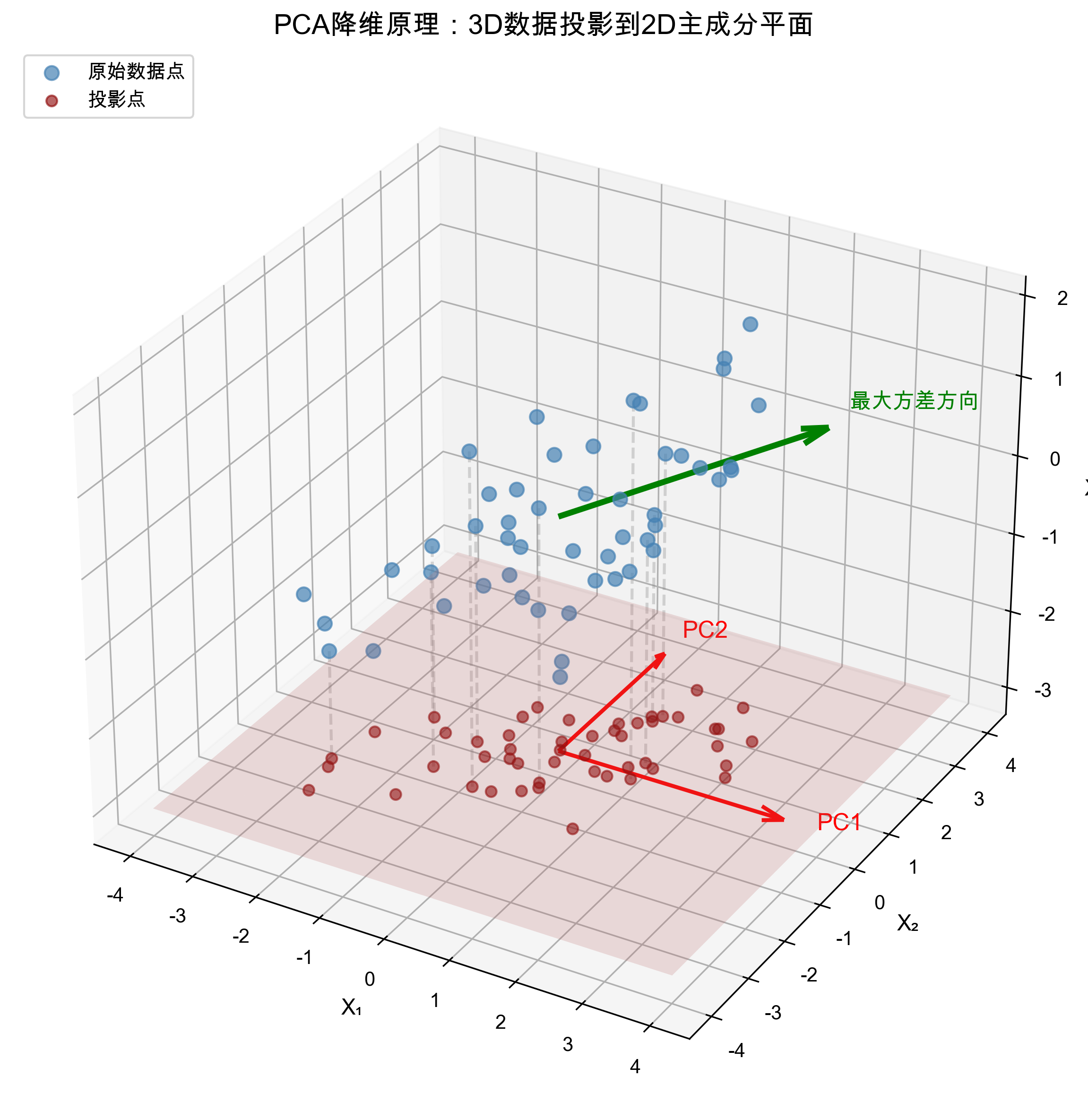
上图解读:
- 蓝色点代表原始高维(3D)数据
- 红色平面是 PCA 找到的最佳投影平面(由 PC1 和 PC2 张成)
- 绿色虚线表示数据点投影到平面的过程
- 投影后的红色叉号保留了数据最大方差方向的信息
核心原理
1. 方差即信息
PCA 认为:数据变化越大的方向,包含的信息越多。
- 如果一个变量在所有样本中都差不多(方差小),它就没啥信息量
- 如果变量差异很大(方差大),它就携带了重要信息
2. 主成分的构造
PCA 通过线性变换,将原始的 个相关变量,转换成 个互不相关的新变量(主成分):
其中:
- 称为主成分(Principal Components)
- 是载荷(Loading),表示原始变量对新成分的贡献
- 各主成分之间互不相关(正交)
3. 主成分的特性
- 第一主成分(PC1):解释数据方差最大的方向
- 第二主成分(PC2):在与 PC1 正交的前提下,解释剩余方差最大的方向
- 以此类推...
数学本质(简化版)
PCA 的数学本质是对协方差矩阵进行特征值分解:
- 数据中心化:减去各变量的均值
- 计算协方差矩阵:
- 特征值分解:
- (特征值):代表该主成分解释的方差大小
- (特征向量):代表主成分的方向(即载荷)
- 选择主成分:按特征值从大到小排序,取前 个
在平台中的应用
适用场景
- 数据探索:初步了解数据的整体结构和分布
- 异常检测:通过 T² 和 SPE 统计量发现异常样本
- 降维可视化:将高维数据投影到 2D/3D 空间观察
- 去噪:剔除噪声成分,保留主要信号
PCA 得分图示例
下图展示了 PCA 分析的典型得分图(Score Plot),每个点代表一个样本,可以直观看到样本的分布模式和异常点:
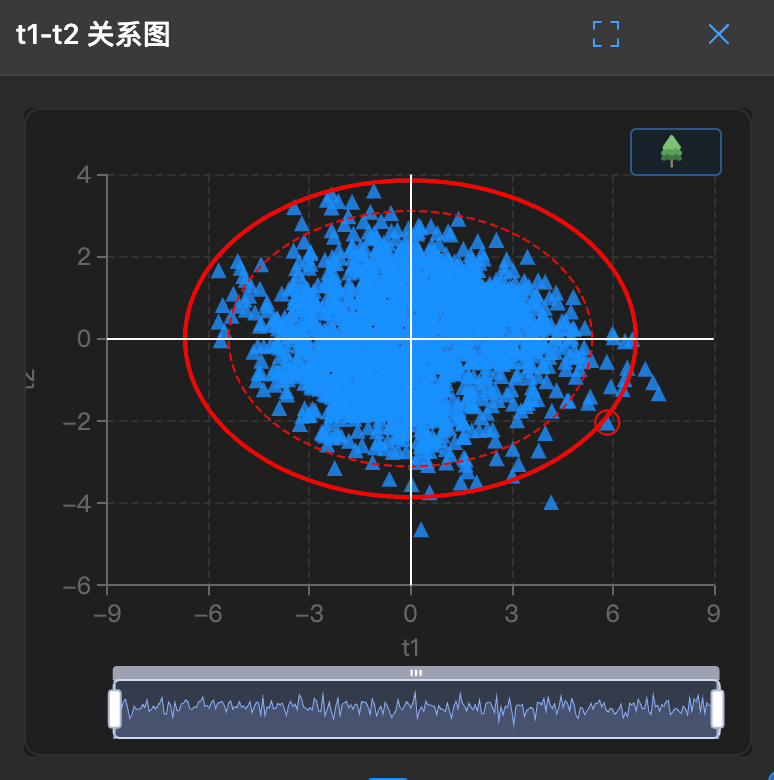
如何解读:
- 每个灰点代表一个样本,位置由其在 PC1 和 PC2 上的得分决定
- 椭圆区域表示置信区间(通常为 95%),圈外的点可能是异常样本
- 聚在一起的点表示相似样本,分散的点表示差异较大
平台自动触发条件
当你只配置了 X 变量(没有 Y 变量)时,平台会自动使用 PCA 模型:
只有 X 列 → 自动选择 PCA → 探索数据结构关键输出指标
| 指标 | 含义 | 解读 |
|---|---|---|
| R²X | X 的累计解释率 | 模型解释了 X 多少信息,越接近 1 越好 |
| 累积贡献率 | 前 k 个主成分的解释比例 | 通常取 80%~95% 即可 |
| 载荷(Loading) | 变量与主成分的关系 | 看哪些变量主导了该成分 |
| 得分(Score) | 样本在新坐标系的坐标 | 用于画散点图观察样本分布 |
主成分数的选择
平台通过交叉验证自动选择最优主成分数,但你可以通过 C+1/C-1 手动调整:
- 太少:欠拟合,信息丢失严重
- 太多:过拟合,引入噪声
- 经验法则:当新增成分对 R²X 贡献 < 5% 时可考虑停止
PCA 的优缺点
✅ 优点:
- 无监督,不需要标签数据
- 计算高效,结果可解释
- 有效降维,去除变量间相关性
- 可视化效果好
⚠️ 局限:
- 只关注 X 的方差结构,不考虑 Y
- 对异常值敏感
- 主成分是线性组合,可能缺乏业务含义
- 假设主成分是正交的,实际数据可能不满足
🔗 PLS(偏最小二乘回归)
什么是 PLS?
PLS(Partial Least Squares Regression,偏最小二乘回归) 是一种有监督的回归方法。与 PCA 不同,PLS 在建模时同时考虑 X(特征)和 Y(目标),寻找一个能最好解释两者关系的潜变量空间。
简单说:PCA 问"X 怎么变化",PLS 问"X 怎么影响 Y"。
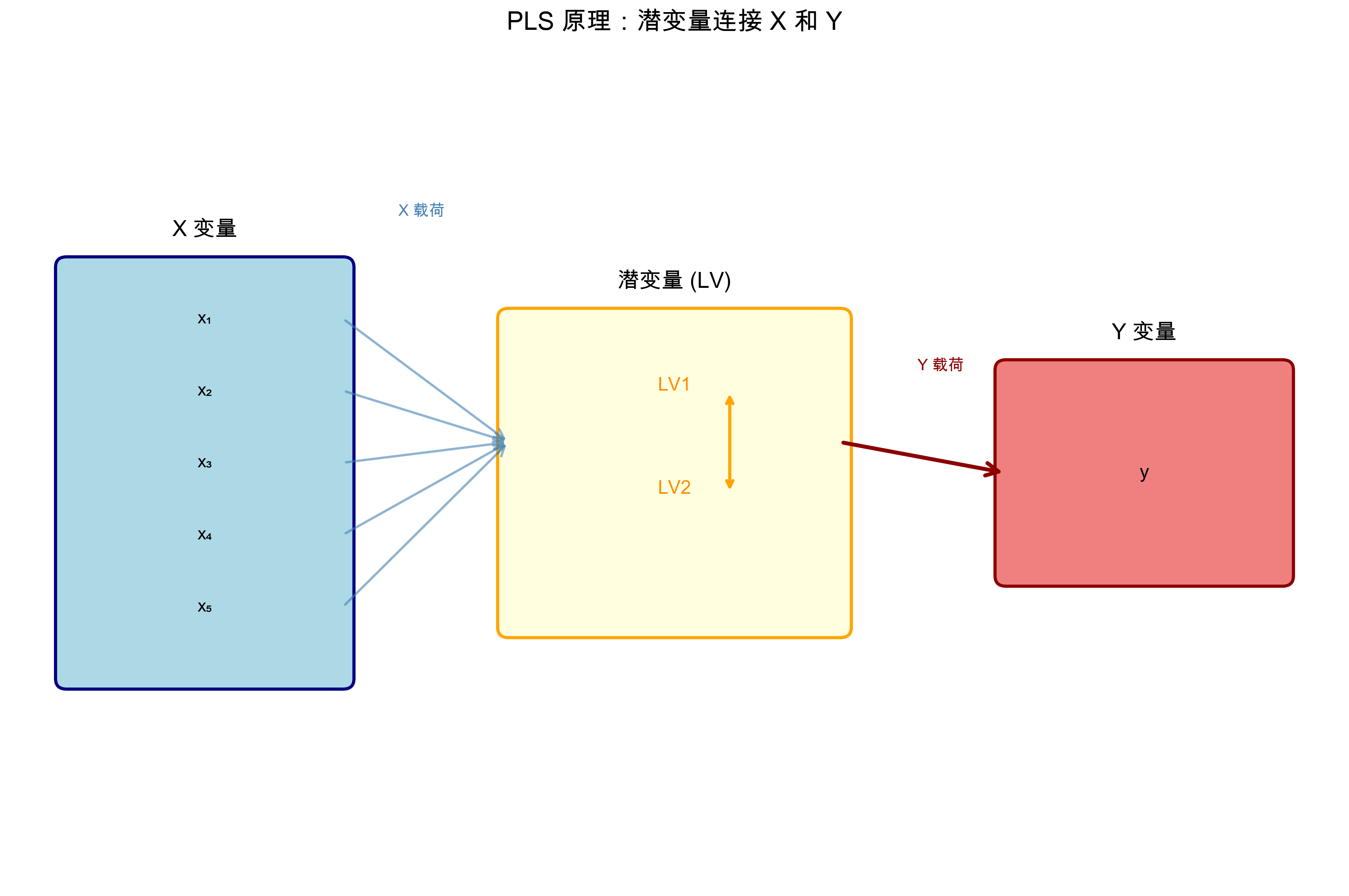
上图解读:
- 左侧蓝色框是 X 变量(X1-X5),右侧绿色框是 Y 变量(目标)
- 中间黄色框是提取的潜变量(LV1, LV2),同时解释 X 和 Y
- PLS 的目标是最大化 X 潜变量与 Y 潜变量之间的协方差
- 通过潜变量建立 X → Y 的预测关系
核心原理
1. 同时分解 X 和 Y
PLS 同时对 X 和 Y 进行分解,但要求两者的潜变量(Latent Variables)最大程度相关:
其中:
- :X 的得分矩阵(与 PCA 的得分类似)
- :X 的载荷矩阵
- :Y 的得分矩阵
- :Y 的载荷矩阵
- :残差矩阵
2. 最大化协方差
PLS 的核心优化目标是:找到 X 和 Y 的潜变量,使它们的协方差最大。
这意味着 PLS 提取的成分,既要能代表 X 的变化,又要与 Y 密切相关。
3. 迭代提取成分
PLS 通过迭代算法(如 NIPALS)逐个提取潜变量:
- 找到 X 和 Y 协方差最大的方向作为第一对潜变量
- 从 X 和 Y 中扣除已解释的部分(去相关)
- 重复直到提取足够的成分
数学本质(简化版)
PLS 的数学核心是协方差最大化:
- 初始化:从 Y 的某列或随机向量开始
- 迭代优化:
- (从 Y 的得分找 X 的权重)
- (计算 X 的得分)
- (从 X 的得分找 Y 的权重)
- (计算 Y 的得分)
- 收敛后:计算载荷
- 去相关:,
在平台中的应用
适用场景
- 回归预测:建立 X → Y 的预测模型
- 变量筛选:通过 VIP 找出对 Y 影响最大的 X 变量
- 多因变量问题:Y 可以是多列(多响应变量)
- 共线性处理:X 变量高度相关时仍稳定
平台自动触发条件
当你同时配置了 X 变量和 Y 变量,且 Y 是连续数值时:
X + Y(连续值) → 自动选择 PLS → 建立回归模型关键输出指标
| 指标 | 含义 | 解读 |
|---|---|---|
| R²X | X 的累计解释率 | 模型捕获的 X 方差比例 |
| R²Y | Y 的累计解释率 | 模型解释的 Y 变异比例,越高越好 |
| Q²Y | Y 的交叉验证预测能力 | 最关键!反映泛化能力,> 0.5 可接受,> 0.9 优秀 |
| RMSE | 均方根误差 | 预测值与真实值的平均偏差,越小越好 |
| VIP | 变量重要性投影 | > 1 表示重要变量,< 0.5 可忽略 |
潜变量数的选择
平台自动通过交叉验证选择最优潜变量数,原则是:
- Q²Y 达到峰值时的成分数最优
- 如果 R²Y 很高但 Q²Y 低 → 过拟合,需要减少成分
- 如果两者都低 → 欠拟合,可能需要增加成分或检查数据
VIP 分析
VIP(Variable Importance in Projection) 是 PLS 的重要输出,告诉你哪些 X 变量对预测 Y 最重要。
下图展示了 VIP 分析的典型结果,柱状图越高表示该变量对 Y 的影响越大:
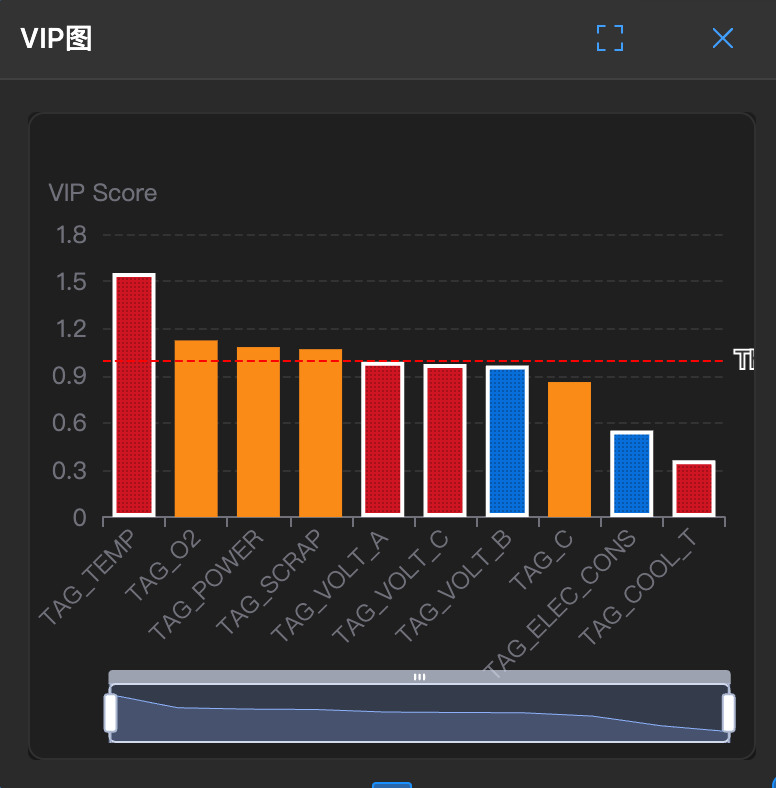
如何解读:
- 红色参考线(VIP = 1)是重要变量的阈值
- 高于红线的变量(如示例中的 x3, x5)对 Y 有显著贡献
- 低于红线的变量可考虑剔除以简化模型
VIP 计算公式:
解读标准:
- VIP > 1:重要变量,对 Y 有显著贡献
- 0.5 < VIP < 1:中等重要
- VIP < 0.5:可忽略,考虑剔除
PLS 的优缺点
✅ 优点:
- 同时处理 X 和 Y,预测能力强
- 有效解决多重共线性问题
- 支持多响应变量(Multi-response)
- 提供 VIP 进行变量筛选
- 样本量小于变量数时仍能工作
⚠️ 局限:
- 需要标签数据(Y)
- 模型解释比 PCA 复杂
- 非线性关系建模能力有限
- 对异常值敏感
🎯 PLS-DA(偏最小二乘判别分析)
什么是 PLS-DA?
PLS-DA(Partial Least Squares Discriminant Analysis,偏最小二乘判别分析) 是 PLS 的扩展,专门用于分类问题。当 Y 是类别标签(如"合格/不合格"、"A 类/B 类/C 类")时,PLS-DA 是你的选择。
简单说:PLS 预测数值,PLS-DA 预测类别。
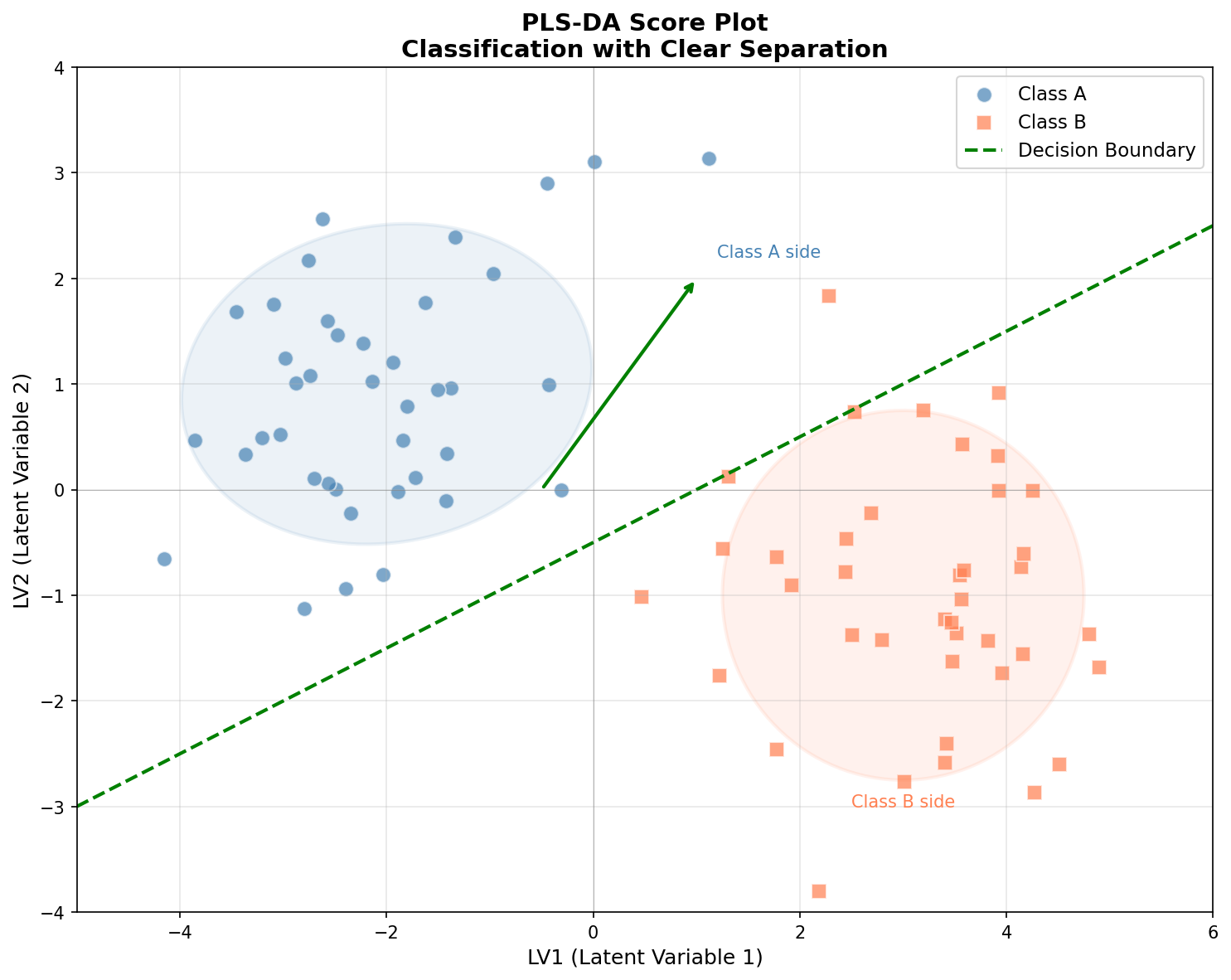
上图解读:
- 蓝色圆点代表 Class A,橙色方块代表 Class B
- 两类样本在潜变量空间(LV1-LV2)中形成明显分离的簇
- 绿色虚线是决策边界,用于区分两类
- 阴影椭圆表示各类的置信区域,重叠越少分类效果越好
核心原理
1. 将分类问题转化为回归问题
PLS-DA 的巧妙之处在于:将类别标签转换为虚拟变量(Dummy Variables),然后用 PLS 进行回归。
例如,三类问题(A、B、C)转换为:
| 样本 | 原始标签 | Y1(A) | Y2(B) | Y3(C) |
|---|---|---|---|---|
| 1 | A | 1 | 0 | 0 |
| 2 | B | 0 | 1 | 0 |
| 3 | C | 0 | 0 | 1 |
然后对这个多响应 Y 矩阵做标准 PLS。
2. 判别规则
预测时,PLS-DA 输出每个类别的"得分",样本被分配到得分最高的类别:
3. 可视化优势
PLS-DA 的得分图(Score Plot)天然适合展示分类效果:
- 不同类别的样本应在图中形成分离的簇
- 第一潜变量通常与组间差异最相关
- 第二潜变量展示组内变异
数学本质
PLS-DA 的数学与 PLS 几乎相同,区别在于 Y 矩阵的构造:
- 编码:将类别标签转换为指示矩阵(Indicator Matrix)
- PLS 回归:对 X 和编码后的 Y 进行标准 PLS
- 判别:预测时选择响应值最大的类别
类别编码方式:
- 二分类:Y = 0/1 或 -1/+1
- 多分类:One-hot 编码(每类一列)
在平台中的应用
适用场景
- 二分类:合格/不合格、阳性/阴性、正常/异常
- 多分类:原料分级、产品分型、品种鉴别
- 特征筛选:找出区分不同类别的关键变量
- 生物标志物发现:医学、组学数据分析
平台自动触发条件
当你配置了 X 变量和 Y 变量,且 Y 是类别标签(文本或离散数值)时:
X + Y(类别标签) → 自动选择 PLS-DA → 建立分类模型关键输出指标
| 指标 | 含义 | 解读 |
|---|---|---|
| R²X | X 的累计解释率 | 模型捕获的 X 方差 |
| Accuracy | 分类准确率 | 预测正确的比例,注意类别不平衡时的陷阱 |
| F1 Score | 精确率和召回率的调和平均 | 类别不平衡时比 Accuracy 更可靠 |
| AUC | ROC 曲线下面积 | 区分能力,0.5 随机,1.0 完美,> 0.8 较好 |
| 混淆矩阵 | 预测 vs 真实分类表 | 直观看出哪类容易混淆 |
| VIP | 变量重要性 | 找出区分类别的关键变量 |
分类性能评估
混淆矩阵解读:
下图展示了 PLS-DA 模型的混淆矩阵,直观显示模型在各类别上的预测表现:
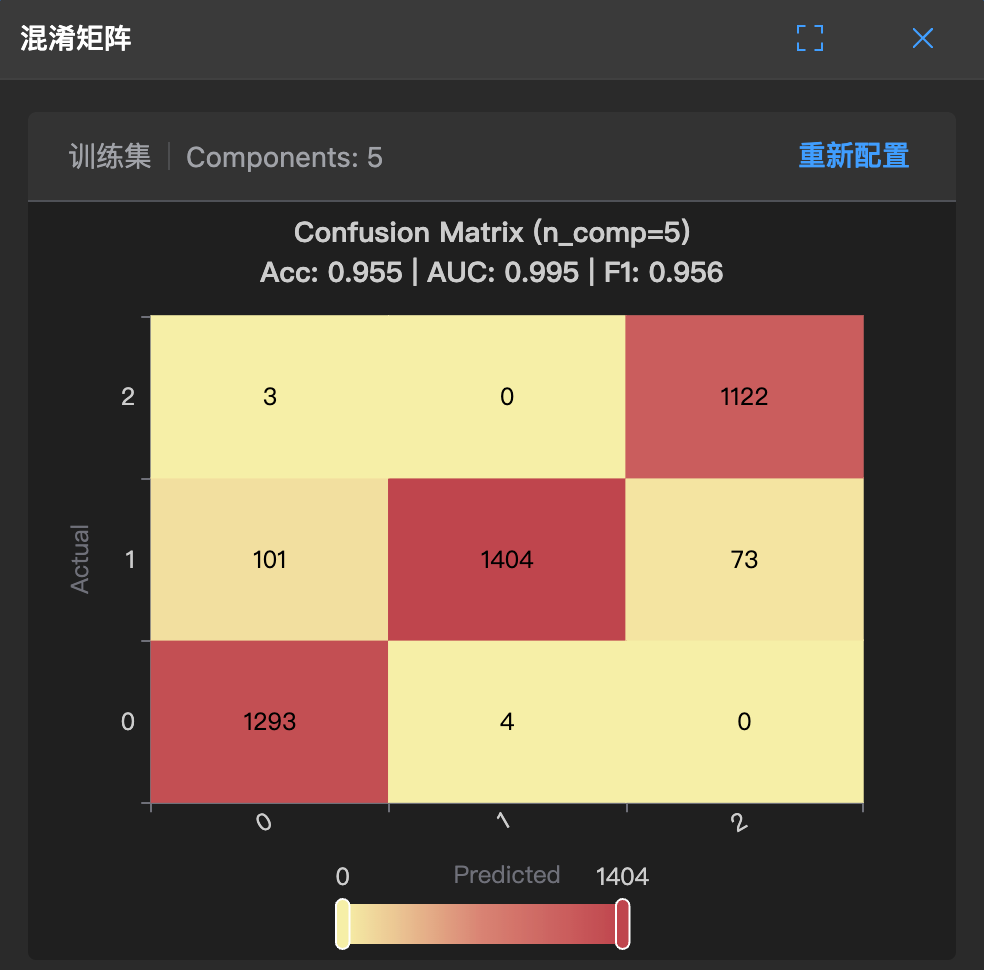
如何解读:
- 对角线上的数值(深色)表示正确分类的样本数
- 非对角线数值表示误分类的样本数
- 理想情况下,所有样本应集中在对角线上
混淆矩阵表格形式:
预测
正类 负类
┌─────────┬─────────┐
真实 │ TP │ FN │
正类 │(真阳性) │(假阴性) │
├─────────┼─────────┤
真实 │ FP │ TN │
负类 │(假阳性) │(真阴性) │
└─────────┴─────────┘衍生指标:
- Precision(精确率): —— 预测为正的有多少是真的
- Recall(召回率): —— 真的正类有多少被找到
- F1 Score: —— 综合指标
类别不平衡时的陷阱:
如果 95% 样本是 A 类,5% 是 B 类:
- 即使模型全部预测为 A,Accuracy 也有 95%
- 但这对 B 类完全无效!
- 解决方案:看 F1 Score、AUC,或调整类别权重
ROC 与 AUC
ROC 曲线:不同阈值下的真正率 vs 假正率
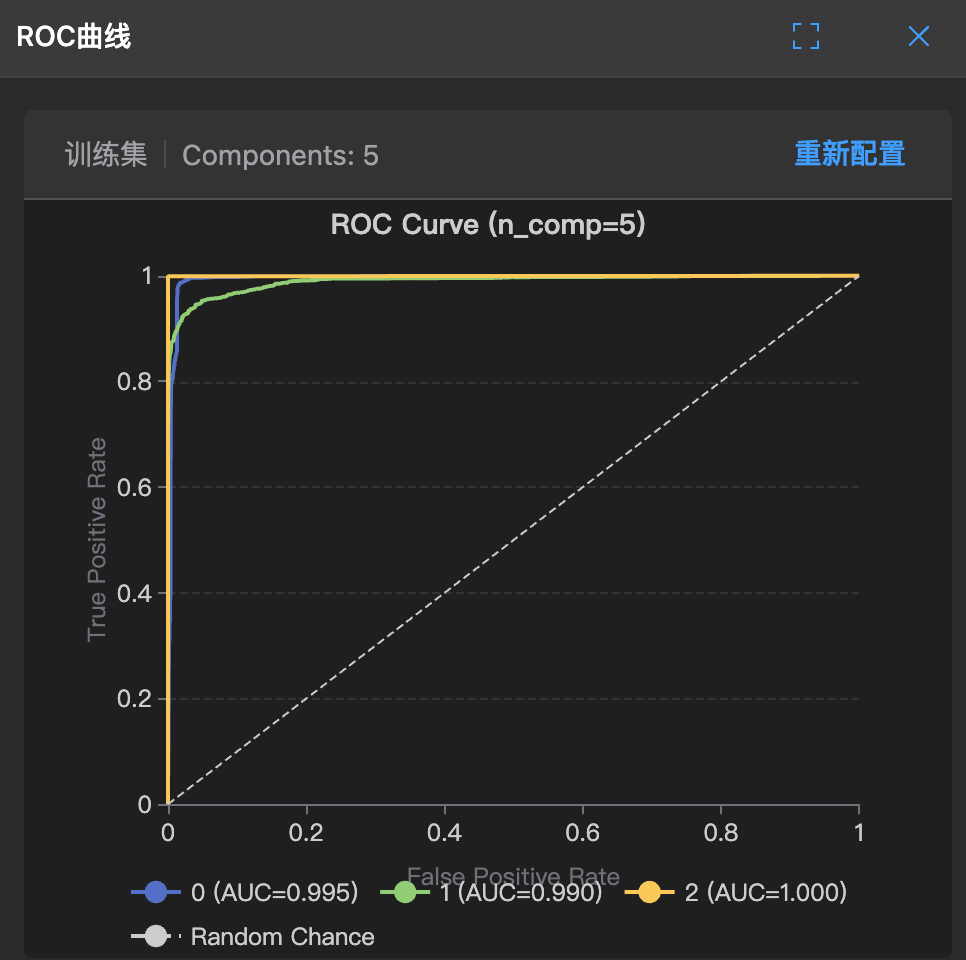
如何解读:
- 曲线越靠近左上角,模型越好
- 对角线 = 随机猜测
AUC 评判标准:
- AUC = 0.5:随机水平(无区分能力)
- 0.7 ≤ AUC < 0.8:可接受
- 0.8 ≤ AUC < 0.9:良好
- AUC ≥ 0.9:优秀
PLS-DA 的优缺点
✅ 优点:
- 适合高维小样本数据(变量数 > 样本数)
- 处理多重共线性
- 提供可视化(得分图展示类别分离)
- 给出 VIP 筛选判别变量
- 比 LDA(线性判别分析)更稳健
⚠️ 局限:
- 假设类别间边界是线性的
- 对类别不平衡敏感
- 过拟合风险(成分数过多时)
- 需要交叉验证严格评估
🔄 三者的对比与选择
快速选择指南
开始
│
▼
┌─────────────────┐
│ 有 Y 变量吗? │
└────────┬────────┘
│
┌─────────┴─────────┐
▼ ▼
否 是
│ │
▼ ▼
┌─────────────┐ ┌─────────────────┐
│ PCA │ │ Y 是什么类型? │
│ 探索结构 │ └────────┬────────┘
│ 发现模式 │ │
└─────────────┘ ┌────────┴────────┐
▼ ▼
连续数值 类别标签
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ PLS │ │ PLS-DA │
│ 回归预测 │ │ 分类判别 │
│ X → Y 关系 │ │ 类别归属 │
└─────────────┘ └─────────────┘详细对比表
| 特性 | PCA | PLS | PLS-DA |
|---|---|---|---|
| 学习类型 | 无监督 | 有监督 | 有监督 |
| Y 变量 | 不需要 | 连续数值 | 类别标签 |
| 主要目的 | 降维、探索 | 回归预测 | 分类判别 |
| 优化目标 | X 方差最大 | X-Y 协方差最大 | 类别分离最大 |
| 输出 | 主成分、得分 | 预测值、VIP | 类别概率、VIP |
| 关键指标 | R²X | R²Y, Q²Y, RMSE | Accuracy, F1, AUC |
| 可视化 | 得分图、载荷图 | 预测图、VIP 图 | ROC 曲线、混淆矩阵 |
| 样本要求 | 无限制 | 样本数 > 变量数较好 | 各类别样本均衡较好 |
组合使用策略
在实际项目中,三种模型往往组合使用:
场景 1:先探索,后建模
1. PCA 探索数据结构 → 发现异常、了解分布
2. 清洗数据 → 剔除异常样本
3. PLS/PLS-DA 建模 → 建立预测/分类模型场景 2:模型诊断
1. PLS 训练模型
2. 用 PCA 思想看得分图 → 检查样本分布
3. 结合 T²/SPE → 识别异常样本场景 3:变量筛选
1. PLS/PLS-DA 计算 VIP
2. 剔除 VIP < 0.5 的变量
3. 重新建模 → 简化模型、提升泛化🛠️ 平台中的建模实践
建模流程
调参技巧
组件数/潜变量数的选择
平台提供 C+1/C-1 按钮手动调整:
| 现象 | 原因 | 解决方案 |
|---|---|---|
| R² 高,Q² 低 | 过拟合 | 减少组件数 |
| R² 和 Q² 都低 | 欠拟合 | 增加组件数 |
| Q² 随组件增加而下降 | 引入噪声 | 选择 Q² 峰值处的组件数 |
交叉验证设置
- K-Fold:样本量大时使用(如 5-fold、10-fold)
- 留一法(LOO):样本量小时使用
- 随机种子:固定种子保证结果可复现
模型诊断清单
训练完模型后,按以下清单检查:
通用检查(所有模型):
- [ ] R²X 是否合理(> 0.5 通常可接受)
- [ ] 得分图是否有明显异常点
- [ ] T²/SPE 是否超限
PLS 专项检查:
- [ ] Q²Y > 0.5(最低门槛)
- [ ] R²Y 与 Q²Y 差距 < 0.2(防过拟合)
- [ ] VIP 高的变量是否符合业务常识
- [ ] 预测散点图是否沿对角线分布
PLS-DA 专项检查:
- [ ] Accuracy > 0.8(视任务难度而定)
- [ ] F1 Score 合理(类别不平衡时必看)
- [ ] AUC > 0.8
- [ ] 混淆矩阵是否有某类特别差
- [ ] 得分图上类别是否明显分离
📚 深入阅读
如果你想更深入理解这些算法,推荐以下资源:
经典文献:
- Wold, S. et al. (2001). PLS-regression: a basic tool of chemometrics
- Trygg, J. & Wold, S. (2002). Orthogonal projections to latent structures (O-PLS)
平台相关图表:
- 模型概要 —— 查看模型整体指标
- 得分图 —— 样本分布可视化
- 载荷图 —— 变量贡献分析
- VIP 图 —— 变量重要性排序
- T² 图 —— 模型内异常检测
- SPE 图 —— 模型外异常检测
- ROC 曲线 —— 分类模型评估
💡 总结
| 模型 | 一句话理解 | 什么时候用 |
|---|---|---|
| PCA | 数据长什么样? | 探索结构、降维、异常检测 |
| PLS | X 如何预测 Y? | 回归问题、建立预测方程 |
| PLS-DA | 属于哪一类? | 分类问题、判别分析 |
掌握这三种模型,你就掌握了星途数据洞察平台的核心。记住:模型是工具,业务理解才是灵魂。 好的分析 = 正确的模型 + 干净 的数据 + 深入的领域知识。
祝你的数据探索之旅顺利!🚀