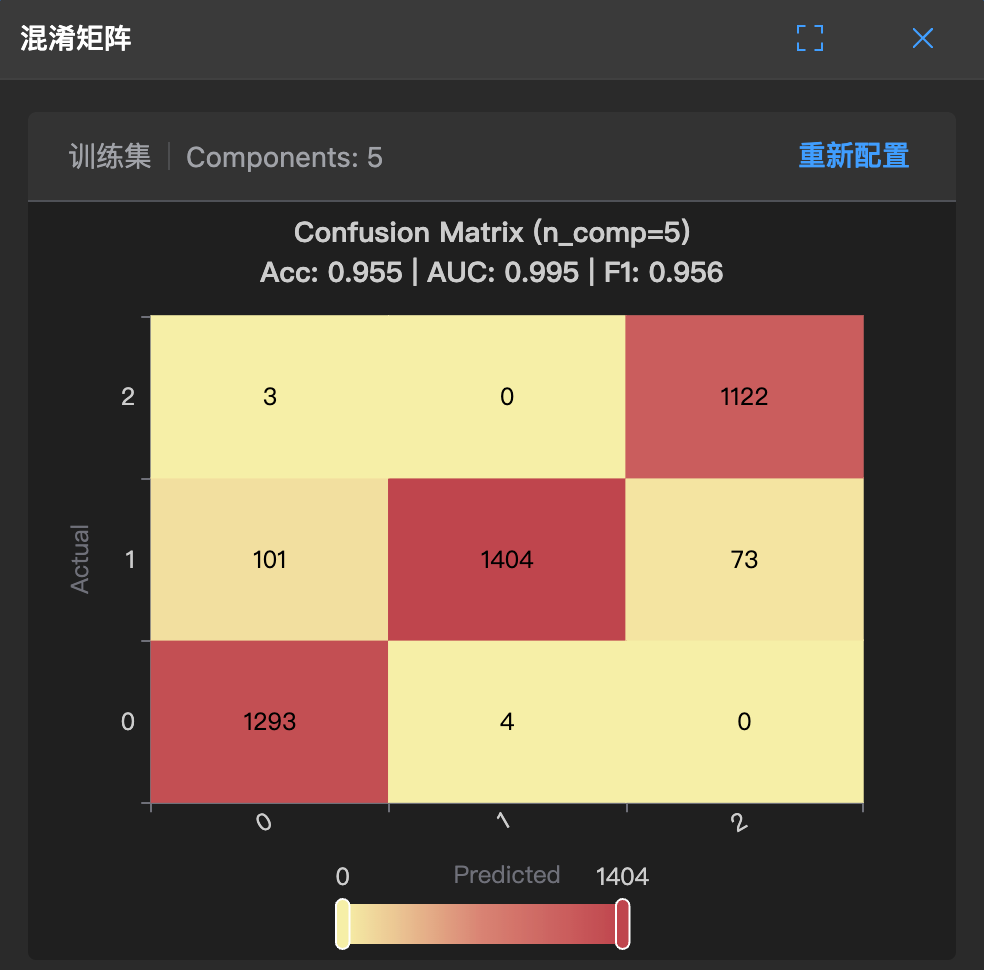
混淆矩阵 (Confusion Matrix) 会员专享
🗺️ 这是什么?
在分类任务中,混淆矩阵就是一份详细的“错题本”。
它不仅告诉你模型考了多少分,还清清楚楚地列出:哪些题做对了,哪些题做错了,错成了什么样。
🧐 怎么看?
矩阵的行和列分别代表:
- Actual(实际):数据真实的类别(垂直方向,如 0, 1, 2)。
- Predicted(预测):模型给出的预测类别(水平方向,如 0, 1, 2)。
1. 找对角线(做对的题)
- 从左上到右下的对角线,代表模型预测正确的数量。
- 比如图中,实际是 0 且预测也是 0 的有 1293 个;实际是 1 且预测也是 1 的有 1404 个。这些格子颜色通常比较深(根 据热力图颜色),数字越大越好。
2. 看非对角线(做错的题)
- 对角线以外的格子,就是模型犯错的地方。
- 比如图中,实际是 2(可能是不合格品),但模型预测成了 0 的有 3 个;实际是 1,模型却预测成了 2 的有 73 个。
- 你可以通过这些格子发现模型的“软肋”:它是不是特别容易把某一类误判成另一类?
3. 看顶部指标 (Acc / AUC / F1)
图表顶部贴心地给出了三个核心指标:
- Acc (Accuracy, 准确率):整体答对的比例(0.955)。
- AUC:整体的区分能力(0.995)。
- F1:综合考虑了精确率和召回率的“端水大师”得分(0.956)。
🛠️ 什么时候用?
- 当你发现模型的准确率(Accuracy)很高,但依然觉得“哪里不对劲”时。
- 特别是在业务代价不同时:比如把“不合格品”误判为“合格品”的代价,远大于把“合格品”误判为“不合格品”。通过混淆矩阵,你 可以清晰地看到这种“致命错误”到底发生了多少次。